
Success Stories
This page includes examples (in no particular order) of “success stories” where data-based methods played a central role in significant materials science advances.
If you have a suggestion for an item to include on this page,
please e-mail to ,
the following information:
|
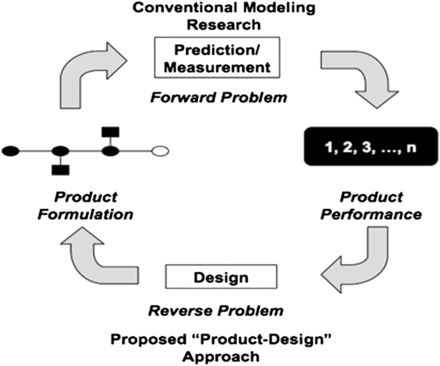
Designing DNA-grafted particles that self-assemble into desired crystalline structures using the genetic algorithm by Babji Srinivasan et al. (PNAS, 110:18431–18435, 2013.)
The traditional, Edisonian method of research involves taking a system and examining its properties. A preferred alternative is to target a suite of properties and then design the most appropriate system in this context. Here we illustrate such a design approach for the self-assembly of colloids grafted with single-stranded DNA. When two types of colloids grafted with complementary ssDNA sequences are mixed, DNA hybridization can lead to the formation of ordered colloidal crystals. We use the genetic algorithm to design ssDNA-grafted particles that will assemble into a desired structure. Our methodology is easily generalizable, fast and highly selective, and not only accurately reproduces the parameters relevant to four currently realized crystals but also elucidates four currently unobserved structures.
|
|
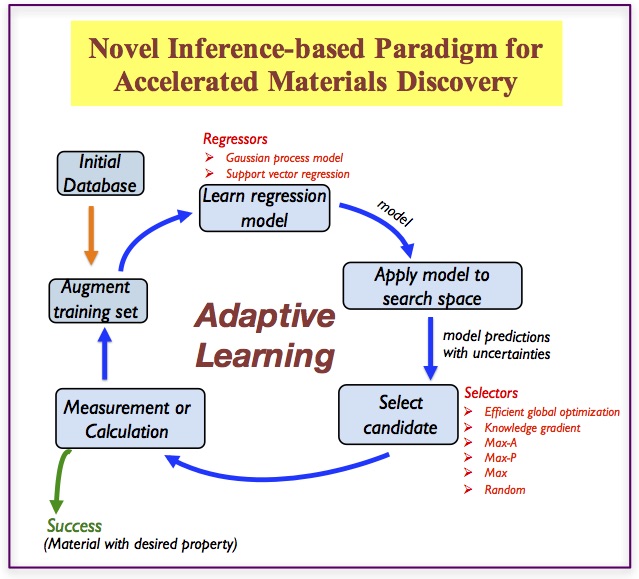
Adaptive strategies for materials design using uncertainties by Prasanna V. Balachandran et al. (Scientific Reports, 6:19660, 2015).
Materials design is an optimization problem, where we seek to find materials with targeted response for a desired application in an accelerated manner. However, the response surface is often complex and multi-modal. We compare several adaptive design strategies using a data set of 223 M2AX family of compounds for which the elastic properties have been computed using density functional theory. The ultimate goal is to obtain a material with desired elastic properties in as few iterations as possible. We examine how the choice of data set size, regressor and selector impact the design. We find that selectors that use information about the prediction uncertainty outperform those that don’t.
|
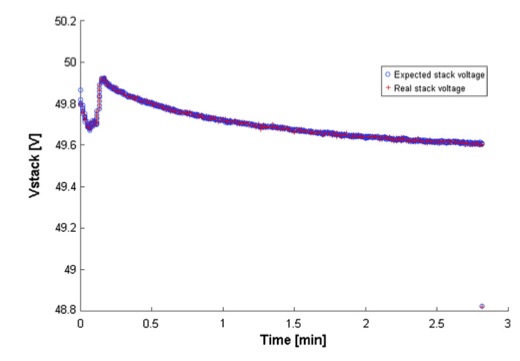
|
Analysis of PEM fuel cell experimental data using principal
component analysis and multi linear regression by Latevi Placca et al. (International Journal of Hydrogen Energy, 35:4582-459, 2010).
Polarisation curves performed at the Fuel Cell System Laboratory (FC LAB) at Belfort on a Proton exchange membrane (PEM) fuel cell stack using a homemade fully instrumented test bench led to more than 100 variables depending on time. Visualising and analysing all the different test variables are complex. In this work, we show how the Principal Component Analysis (PCA) method helps to explore correlations between variables and similarities between measurements at a specific sampling time (individuals). To complete this method, an empirical model of the PEM fuel cell is proposed by linking the different input parameters to the cell voltage using Multiple Linear Regression. This model is in excellent agreement with experiment as shown in the figure.
|
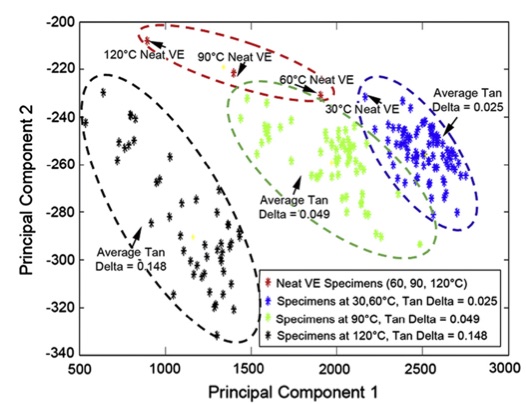
|
Data mining and knowledge discovery in materials science and engineering: A polymer nanocomposites case study by Osama Abuomar et al. (Avanced Engineering Informatics, 27:615-624, 2013).
In this study, data mining and knowledge discovery techniques were employed to validate their efficacy in acquiring information about the viscoelastic properties of vapor-grown carbon nanofiber (VGCNF)/vinyl ester (VE) nanocomposites solely from data derived from a designed experimental study. Formulation and processing factors (VGCNF type, use of a dispersing agent, mixing method, and VGCNF weight fraction) and testing temperature were utilized as inputs and the storage modulus, loss modulus, and tan delta were selected as outputs. The data mining and knowledge discovery algorithms and techniques included self-organizing maps (SOMs) and clustering techniques. SOMs demonstrated that temperature had the most significant effect on the output responses followed by VGCNF weight fraction. SOMs also showed how to prepare different VGCNF/VE nanocomposites with the same storage and loss modulus responses. A clustering technique, i.e., fuzzy C-means algorithm, was also applied to discover certain patterns in nanocomposite behavior after using principal component analysis as a dimensionality reduction technique. Particularly, these techniques were able to separate the nanocomposite specimens into different clusters based on temperature and tan delta features as well as to place the neat VE specimens (i.e., specimens containing no VGCNFs) in separate clusters (see figure). Most importantly, the results from data mining are consistent with previous response surface characterizations of this nanocomposite system. This work highlights the significance and utility of data mining and knowledge discovery techniques in the context of materials informatics.
|
|
Materials Informatics: The Materials “Gene” and Big Data by Krishna Rajan (Annual Review of Materials Research, 45:153-169, 2015).
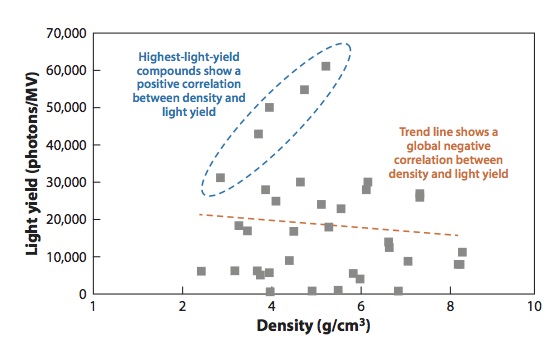
Materials informatics provides the foundations for a new paradigm of materials discovery. It shifts our emphasis from one of solely searching among large volumes of data that may be generated by experiment or computation to one of targeted materials discovery via high-throughput identification of the key factors (i.e., “genes”) and via showing how these factors can be quantitatively integrated by statistical learning methods into design rules (i.e., “gene sequencing”) governing targeted materials functionality. However, a critical challenge in discovering these materials genes is the difficulty in unraveling the complexity of the data associated with numerous factors including noise, uncertainty, and the complex diversity of data that one needs to consider (i.e., Big Data). In this article, we explore one aspect of materials informatics, namely how one can efficiently explore for new knowledge in regimes of structure-property space, especially when no reasonable selection pathways based on theory or clear trends in observations exist among an almost infinite set of possibilities. The figure shows a plot linking variations in light yield with materials density for newly predicted compounds using fuzzy descriptors.
|

|
Machine-learning-assisted materials discovery using failed experiments by Paul Raccuglia et al. (Nature, 533:73-76, 2016).
We demonstrate an approach that uses machine-learning algorithms trained on
reaction data to predict reaction outcomes for the crystallization of
templated vanadium selenites. We used information on ‘dark’
reactions—failed or unsuccessful hydrothermal syntheses—collected from
archived laboratory notebooks from our laboratory, and added physicochemical
property descriptions to the raw notebook information using cheminformatics
techniques. We used the resulting data to train a machine-learning model to
predict reaction success. When carrying out hydrothermal synthesis
experiments using previously untested, commercially available organic
building blocks, our machine-learning model outperformed traditional human
strategies, and successfully predicted conditions for new organically
templated inorganic product formation with a success rate of 89 per cent.
Inverting the machine-learning model reveals new hypotheses regarding the
conditions for successful product formation.
|
|
Inverse dynamical photon scattering (IDPS): an artificial neural network
based algorithm for three-dimensional quantitative imaging in optical
microscopy by Xiaoming Jiang et al. (Optical Express, 24:7006-7018, 2016).
IDPS, is an artificial neural network based algorithm for three-dimensional
quantitative imaging in optical microscopy. Because the inverse problem
entails numerical minimization of an explicit error metric, it becomes
possible to freely choose a more robust metric, to introduce regularization
of the solution, and to retrieve unknown experimental settings or microscope
values, while the starting guess is simply set to zero. Regularization is
accomplished through an alternate directions augmented Lagrangian approach,
implemented on a graphics processing unit. These improvements are
demonstrated on open source experimental data (L. Tian, “3D FPM on LED array
microscope” (2015) available here),
retrieving three-dimensional amplitude and phase for a thick specimen.
|
|
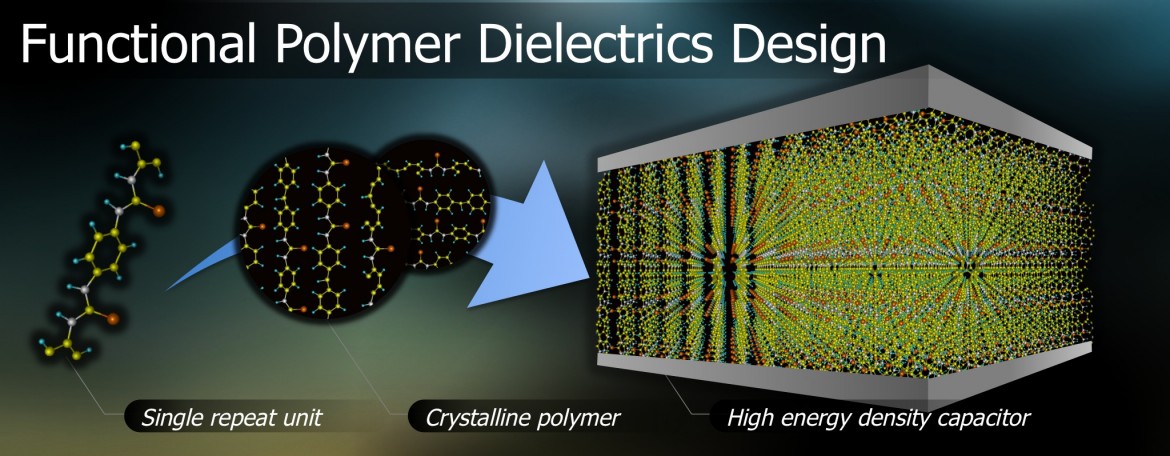
Rational Co-Design of Polymer Dielectrics for Energy Storage,
by Arun Mannodi-Kanakkithodi et al. (Advanced Materials, 28:6277-6291, 2016).
We have demonstrated how one may harness a rational co-design approach involving
synergies between (1) high-throughput computational screening and
machine learning, and (2) experimental synthesis and testing with the
example of polymer dielectrics design for electrostatic energy storage
applications. These efforts can potentially enable going beyond
present-day "standard" polymer dielectrics (such as biaxially oriented
polypropylene), and have led to the identification of several new organic
polymer dielectrics within known generic polymer subclasses (e.g.,
polyurea, polythiourea, polyimide), and the recognition of the untapped
potential inherent in entirely new and unanticipated chemical subspaces
offered by organometallic polymers. Our results can be explored online at
http://polymergenome.org.
|
|
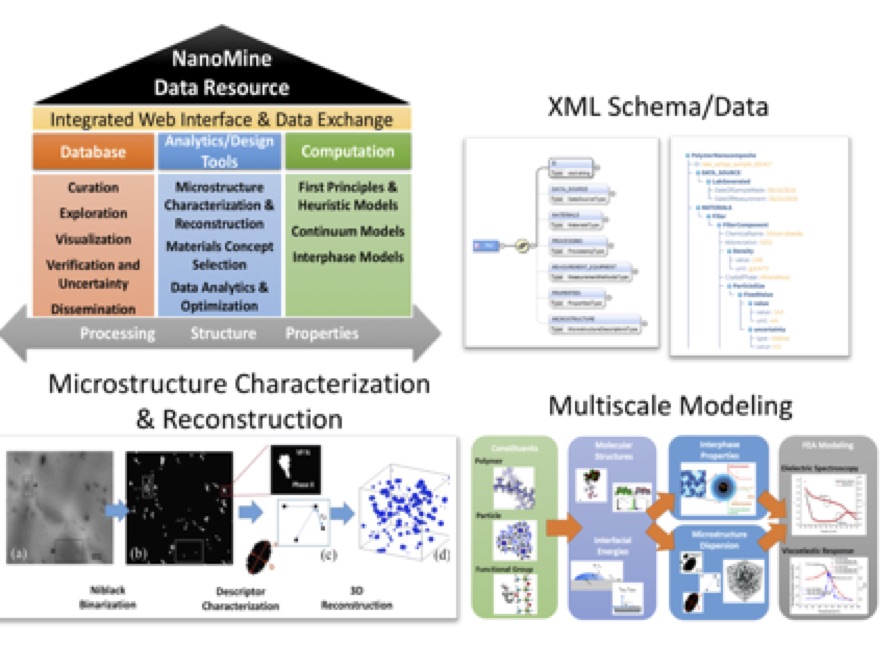
NanoMine: A material genome approach for polymer nanocomposites analysis and design by He Zhao et al. (APL Materials, 4:053204, 2016).
Polymer nanocomposites are a designer class of materials where nanoscale particles, functional chemistry and polymer resin combine to provide materials with unprecedented combinations of physical properties. In this paper, we introduce NanoMine, a data-driven web-based platform for analysis and design of polymer nanocomposite systems under the Material Genome concept. This open data resource strives to curate experimental and computational data on nanocomposite processing, structure and properties, as well as to provide analysis and modeling tools that leverage curated data for material property prediction and design. With a continuously expanding dataset and toolkit, NanoMine encourages community feedback and input to construct a sustainable infrastructure that benefits nanocomposite material research and development.
|